什么是威胁建模
威胁建模是一种分析应用程序安全性的结构化方法,可以用来识别、量化和降低应用程序安全风险。主要管理流程包含如下:
- 标识资源:找出系统必须保护的有价值的资源
- 创建总体体系结构:利用简单的图表来记录应用程序的体系结构,包括子系统、信任边界和数据流。
- 分解应用程序:分解应用程序的体系结构,包括基本的网络和主机基础结构的设计,从而为应用程序创建安全配置文件。安全配置文件的目的是发现应用程序的设计、实现或部署中的缺陷。
- 识别威胁:牢记攻击者的目标,利用对应用程序的体系结构和潜在威胁的了解,找出可能影响应用程序的威胁
- 记录威胁:利用通用模板记录每种威胁,该模板定义了一套要捕获的各种威胁的核心属性
- 评价威胁:对威胁进行评价以区分优先顺序,并首先处理最重要的威胁。这些威胁带来的危险最大。评价过程要权衡威胁的可能性,以及攻击发生时可能造成的危害。评价的结果可能是:通过对此威胁带来的风险与为使威胁得到减少所花费的成本,对于某些威胁采取的行动是不值得的
- 缓解方案:对列出的各类威胁,提出缓解方案,解决风险,是威胁建模的最终
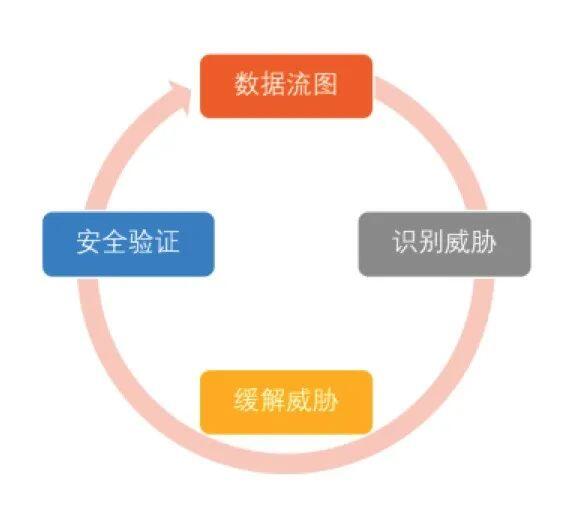
- 安全验证:在系统完成开发后,通过安全测试验证各缓解方案的实现情况,对未完成的安全需求,则重新转入设计、编码流程,直至风险消除。
何时做威胁建模?
在软件开发生命周期中,设计阶段是对需求分析结果进行软件系统整体设计的重要阶段。相比在系统完成开发后再考虑安全需求,提前在设计阶段就完成整体安全方案设计,不管对开发人员还是安全人员,都有更大的弹性空间提前消除安全威胁,避免类似事后打补丁式的被动防御,同时也有助于降低开发和后期维护的成本。通过安全设计消除潜在的威胁,并在测试环节进行安全测试验证,形成一个设计-实现-验证闭环。绝大部分安全威胁,可以通过威胁建模来实现。
如何做威胁建模
STRIDE威胁建模方法。还有基于STRIDE威胁建模方法的SDL Threat Modeling Tool[2]威胁建模工具,该工具可以帮助安全人员画数据流图、分析威胁、生成并导出威胁建模报告。
STRIDE介绍
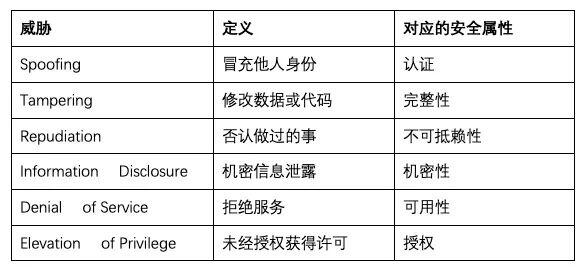
STRIDE威胁建模将威胁类型分为Spoofing(仿冒)、Tampering(篡改)、Repudiation(抵赖)、Information Disclosure(信息泄漏)、Denial of Service(拒绝服务)和 Elevation of Privilege(权限提升),共6个维度,几乎可以涵盖目前绝大部分安全问题。
威胁建模流程
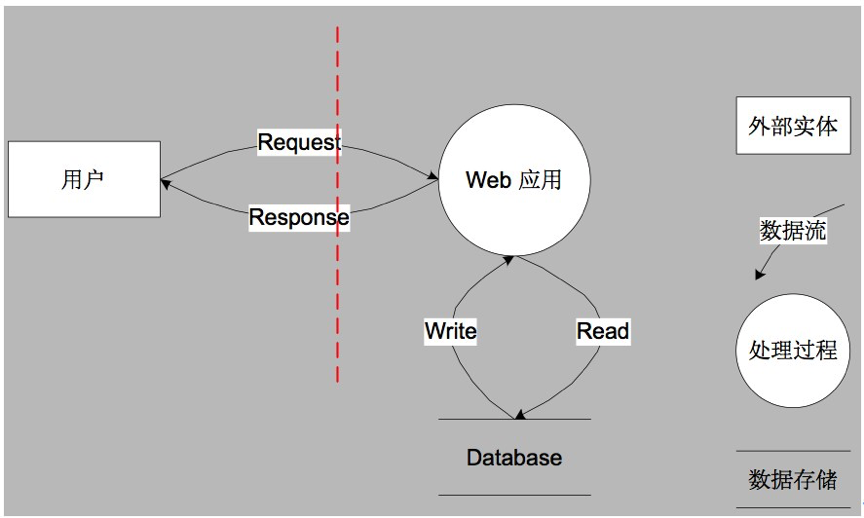
数据流图
STRIDE建模的第一步就是分解业务场景,绘制数据流图(DFD)。威胁建模针对的是一个个具体场景,所以首先需要对我们的系统根据实际情况进行业务场景的分解,比如登录场景、交易场景、审批场景、灾备场景等等,具体是什么场景以及有多少个场景,是和实际的系统和业务息息相关的。分解完业务场景以后,就对一个一个的场景分别进行STRIDE威胁建模,每个场景的STRIDE威胁建模是相对独立的。 首先对一个具体的场景绘制数据流图(DFD),一个简单Web应用的数据流图如下所示:
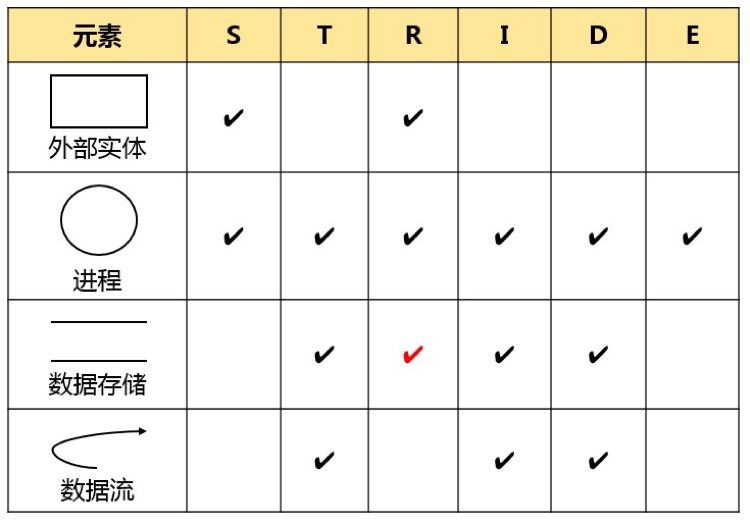
识别威胁
STRIDE威胁建模方法已经明确了每个数据流图元素具有不同的威胁,其中外部实体只有仿冒(S)、抵赖(R)威胁,数据流只有篡改(T)、信息泄露(I)、拒绝服务(D)威胁,处理过程有所有六种(STRIDE)威胁,存储过程有篡改(T)、信息泄露(I)、拒绝服务(D)威胁,但如果是日志类型存储则还有抵赖(R)威胁。具体可以对照如下表格进行威胁识别:
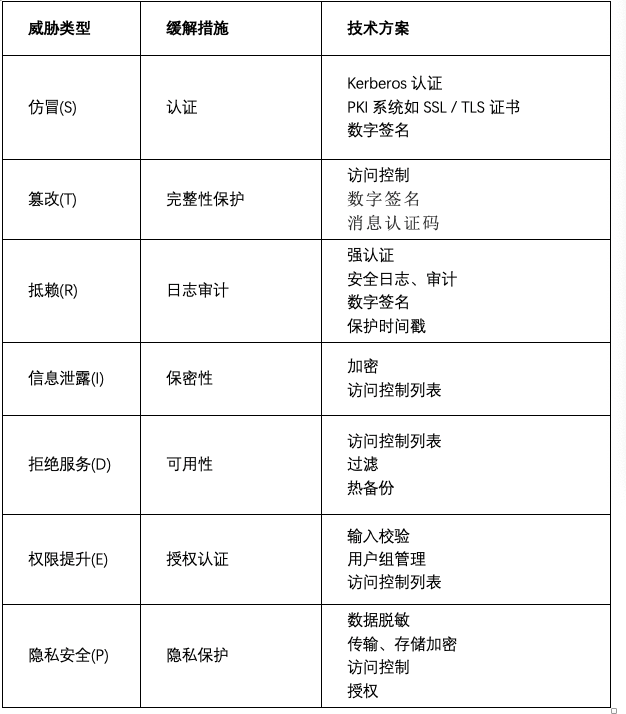
缓解措施
根据不同的数据流图元素及威胁,相应的缓解措施也不相同。下表是一些威胁类别的通用性缓解方案:
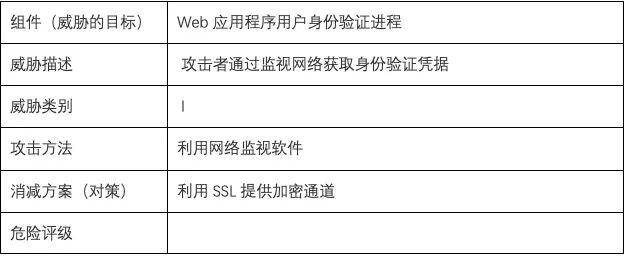
分析完数据流图中的所有对象的潜在威胁以后,就要输出一个威胁列表,威胁列表中的每个威胁项如下表:
安全验证
在威胁建模完成后,需要对整个过程进行回顾,不仅要确认缓解措施是否能够真正缓解潜在威胁,同时验证数据流图是否符合设计,代码实现是否符合预期设计,所有的威胁是否都有相应缓解措施。最后将威胁建模报告留存档案,作为后续迭代开发、增量开发时威胁建模的参考依据。



